We have released a new update of chunkx. We would like to briefly introduce one function from the update: Learning Objectives. From now on, our authors can add learning objectives to their channels in chunkx creator. This allows learners to be given a performance target and the results to be stored for documentation purposes.
What do "learning objectives" mean exactly?
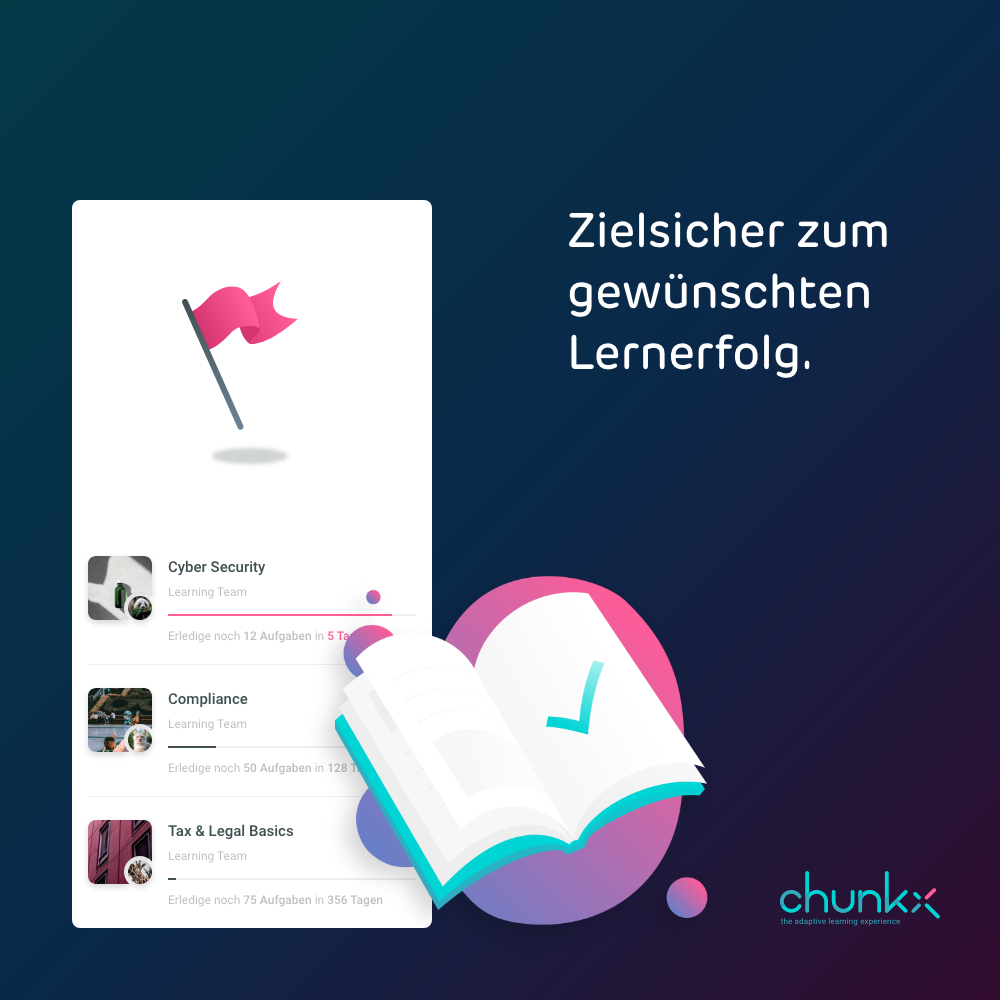
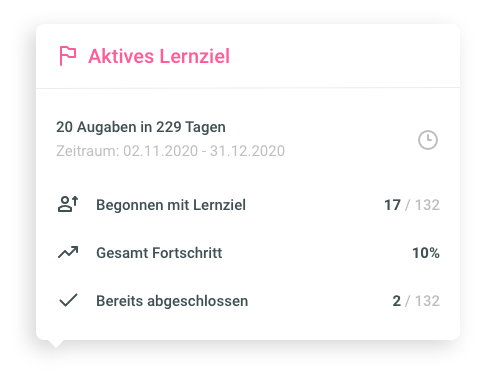
Learning objectives complement your channels in chunkx and give learners specific targets. E.g. that 10 microlearning units must be worked on in 6 months and the tasks for this must be answered correctly. While authors cannot access the evaluations of individual users, they can see who has already completed it in the learning objectives. The purpose behind this is that learning objectives are often used for topics where completion must be demonstrated and documented.
What settings are possible?
Authors can define whether tasks of the microlearning units have to be edited only or solved correctly. You can select how many microlearning units need to be processed and you can define the time period. It is possible to define optionally and to the day a time period for the respective learning goal.
The learning target can be repeated automatically. For example:
yearly,
weekly,
monthly and
quarterly.
In this way, learners get the appropriate support they need. This is how easy it is to promote continuous and sustainable learning, tailored to your own prior knowledge, with chunkx.
What is the difference to certificates in the LMS?
In typical eLearnings, a distinction is made between participation and passing the final test; in chunkx, learning objectives are instead controlled based on the micro-learning units. The learning objectives in chunkx can thus be set up in a smaller way and repeated more frequently. Instead of going through a 30-minute web-based training 1x a year, learning objectives can be set so that, for example, 1x a quarter up to 5 microlearning units have to be completed.
The effect is immediately apparent: learners benefit from more frequent repetition and moments of reflection. What is learned is not simply forgotten and is available when needed. The selection of microlearning content is adaptive and always adjusts to the individual.
More information and contact
You can find more on our page about learning objectives in chunkx and in the chunkx creator.
Is the topic relevant to you? Contact us to schedule a personal presentation appointment. We’ll then look together at how you and your organization can best benefit from the new features and how we can interface with your other learning systems as needed.
How can trainers, instructional designers, and eLearning authors properly use learning tasks? How do we use it to stimulate learning processes and not just test them? How do we go beyond learning factual knowledge with closed tasks? Learn more in this two-hour workshop. We are looking forward to your registration.
Where: Online in MS Teams. Link follows after invitation.
Target audience: The content is aimed at trainers, instructional designers, eLearning authors.
Trainer: The workshop will be conducted by Florian Stieler, graduate educator, CEO & founder of chunkx and passionate digital learning creator. Author of the book Validität summativer Prüfungen (Validity of Summative Examinations ), in which the design of learning tasks is a major topic.
Cost: No cost, only high quality.
Registration: Via the contact form below – first come first serve.
Adaptive learning and content sorting: Putting learning content in a meaningful order is one of the most basic tasks in creating digital learning content. In our authoring tool chunkx creator, we have recently started to offer our authors the possibility to either give a topic a fixed order or to let our algorithm choose the content according to the order. of the learner profile, i.e., to be selected adaptively. A fixed sequence is suitable, for example, when a topic is presented for the first time. Adaptive assignment, on the other hand, is more suitable when learning content is to be selected to complement training.
In this article, we explain why the settings option is so helpful, what the advantages and disadvantages of the two variants are, and describe in more detail how adaptive learning works in chunkx.
Structuring of learning content
Learning videos, web-based trainings, webinars or trainings: the content in each of these units has been put into an order that makes sense from her/his point of view by a trainer or author. In the best case, this is preceded by a definition of the learning objectives: What should the participants have learned after the measure?
Once the learning objectives are available, the learning time and format must be defined. Both aspects are cost drivers, so decisions are not made solely according to didactic parameters, but also according to economic ones.
Now we finally come to the structuring of the content: How do you give the participants the necessary context? Do you first describe a topic on an abstract level and then give an example, or vice versa? When are good times for exercises and discussions? As you can see, it is not possible to describe a one-size-fits-all approach, as all factors have to be taken into account: Learning objectives, formats, premises, time, budget, the type of content, its complexity, etc.
Experienced didacticians have already noticed which factor we have not yet listed: The participants.
Participants:inside are the most heterogeneous factor
As if it were not complicated enough, we develop our learning activities for a varying number of individual participants. Some learn best inductively, that is, first by concrete examples and then by theory. For others it’s the other way around, they want to understand the theory before they get to the examples.
Participants bring different levels of prior knowledge with them. While some first have to carefully understand the context and gain basic knowledge, others are already ten steps further and are impatiently waiting for the content that is exciting for them to finally follow.
In addition, there are other factors, such as the communication between the participants, the speed of learning or hierarchical behaviors that require different approaches.
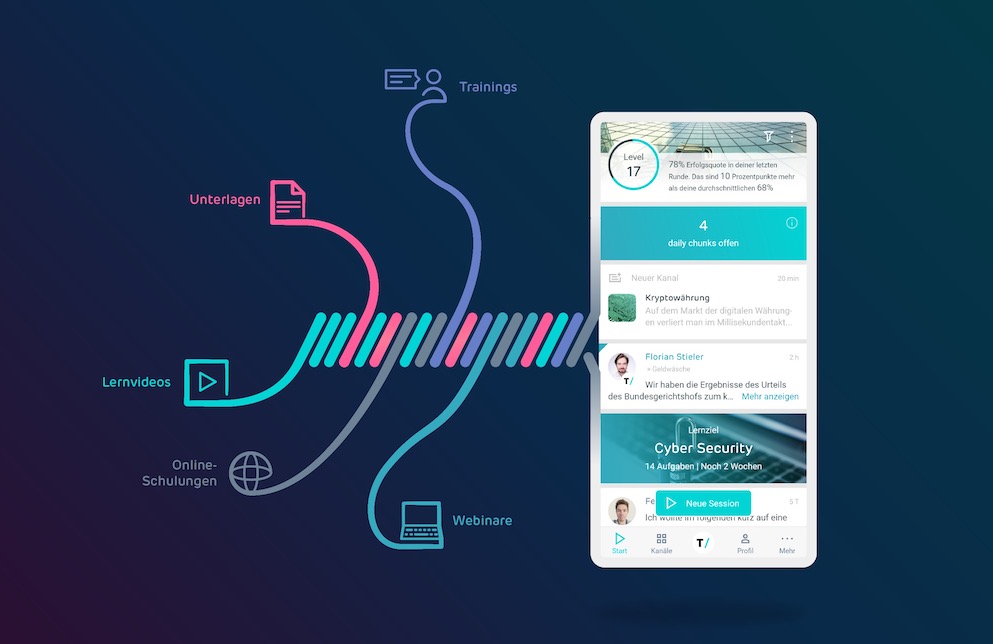
In classroom trainings and webinars there are usually between 5 and 30 participants. But learning videos and web-based trainings are often created for several thousand participants. That’s why we developed chunkx to enable adaptive learning automatically and without any effort on the part of the author – whether for five or several thousand users.
Learning in chunkx – this is how it works
In chunkx, content is broken down into learning tasks as the smallest possible interactive formats. Learning tasks have the advantage that they not only stimulate memory, association and learning processes, but also make productive use of the user’s time: If I can already do something, it will only take me a few seconds to complete it. If I can’t do something yet, I deal with it more intensively. The tasks always contain all the necessary learning content, integrate images and videos, or refer in the feedback to sources that describe the content in even more detail – such as a web-based training or a blog article.
A wide variety of measures can be supplemented with chunkx and bundled there
The learning tasks are also supplemented by a timeline on which users can receive pre-programmed or manually sent messages from authors. In turn, they learn how many users have responded to their posts and what is more and less interesting to them.
By combining a micro-learning format with data that reflects the interests and knowledge of users, our algorithm creates individual learning paths across any number of topics. Quite automatically and without complex programming, the strengths of the users are given less priority than the weaknesses and learning content is continuously repeated according to the respective user difficulty.
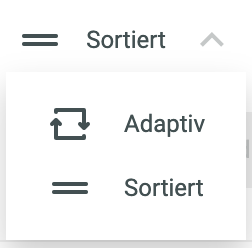
Sorting instead of adaptive allocation
Let’s imagine a channel with 40 learning tasks. Adaptive allocation means that task #39 is shown first to one user, task #1 to another, or task #20 to yet another user. In order to provide users with a fixed order, authors can change the channel in chunkx from adaptive to sorted at any time. As a result, new content from the channel is presented in exactly the order the author deems most appropriate. The emphasis here is on “new” content. Because repetitions are always used in chunkx according to. of the learner’s individual data, i.e., adaptively assigned.
Adaptive vs. sorted – which is the better choice when?
Switch easily between adaptive and sorted in the chunkx creator
Adaptive
Let’s think back to the complexity of sorting learning content described at the beginning. Here, chunkx offers authors the chance to exploit the possibilities of digital solutions and to rely on the support of our algorithm when it comes to the user-specific selection of learning content. In the following scenarios, this makes especially much sense:
1. supplementation of learning measures
With chunkx, trainings, webinars, webbased trainings can be easily extended. When the above measures end, content can be repeated and reinforced via chunkx. And since repetitions should be based on the individual level of knowledge and not on a fixed order that applies to everyone, the “adaptive” setting is the best choice here.
2. many equivalent contents
Sometimes topics consist of many knowledge units that do not so much build on each other, but stand neutrally next to each other. This can be the case of legal and regulatory content, but also when you want learners to apply learned knowledge to new contexts through a variety of application scenarios. Here, too, we believe that the “adaptive” setting is the best way to efficiently present users with the content that is relevant to them.
3. particularly heterogeneous target groups
The larger and more diverse the target users are, the more difficult it is to define a successful fixed sequence of learning content. Of course, it is also possible to prepare channels for different target groups differently in chunkx – e.g. a separate variant only for executives – but even after such a division, the participants are still too different, then a content selection makes sense according to the “chunkx” concept. We write “possibly” deliberately, because here the advantages described below for the “sorted” setting must be weighed carefully against those described above.
Sorted
The “sorted” setting offers authors other possibilities and advantages, especially in the following situations:
1. new contents
If chunkx is not used subsequently to another measure, but presents content as a learning unit to users for the first time, a predefined structure of the content is suitable. In this case, too, the learning time of the individual user:s is used more productively than in other learning formats, because familiar content costs them little time and unfamiliar content is repeated selectively. The fixed sorting applies only to “new” content that users have not yet edited.
2. strong narrative
At its best, learning content should inspire and engage us. And we believe that you can do this even with the most supposedly boring topic. In adaptive micro-learning, we face the particular challenge of ensuring that we chop up content as much as possible so that we can, in turn, arrange it in a flexible and user-specific way. However, this also means that successful scenarios, pictorial descriptions, emotionalizing narratives can only be built up within a single micro-unit, since we do not know for sure what users have already processed and what not. Sorting learning content can overcome this hurdle. You can now be sure that the thread within the topic is maintained and you know exactly that all user:in step by step through the same texts, images, videos and exercises wander.
Sorted vs. adaptive – the authors decide
In our authoring tool chunkx creator, authors decide which setting suits their channel. Helpful tips help with the selection and it is also possible to change the setting again after go-live: If a channel is put online with the setting “adaptive” and you realize after a short time that a sorting would be more suitable after all, this can be adjusted immediately. The order of the content can also be changed and readjusted at any time.
With chunkx, we want to sort large amounts of learning content in a user-specific way. To do this, it is essential to automatically analyze the learning content and relate it to each other. We use Natural Language Processing techniques to make this possible. Find out exactly how this works and what it means for our users, our learning app, and corporate training in this article. Have fun reading!
User-specific learning, without programming effort for the authors
chunkx supplements or replaces existing learning with continuous micro-learning. But what does continuous learning mean in an operational context? Well, typical trainings, e-learnings, learning videos, webinars, etc. end at a certain point – sometimes with and sometimes without a knowledge test. This limitation is a high risk in terms of time for the individual and economically for the paying company: because after just a few days, we forget a large part of what we have learned. Ebbinghaus figures that after 6 days we only know 23% of what we learned. Regardless of the significance of this specific figure, with chunkx we are taking on the challenge of flattening the forgetting curve.
Repetition and linkage
A first step towards this is the repetition of learned content. For this purpose, we use learning tasks followed by explanatory feedback in chunkx. he content we learn from a wide range of different areas – be it subject-specific content, regulations, new skills, or perennial favorites such as security, safety, and compliance – must be brought together in user-specific feeds. However, every user has limited time, which is why their respective feed should ideally prioritize content that they want to or should learn, but don’t yet know as well as others. With 10 topics with learning content of one hour each and a learner who can invest just a few minutes per week in continuous repetition, the question is how to succeed in this challenge? And how can additional recommendations for new content be made to learners based on this?
chunkx creator: tagging the content
In order to compile learning content as appropriately as possible and individually, it is necessary to relate it to each other. On the first level, this is done via channels: All learning content, e.g. on the topic of tax law, is assigned to the corresponding channel. But what does it look like within the channel, which content belongs together there and how? And maybe there is suitable content outside this channel?
For this, we already enable our authors to tag learning content. Different learning tasks are linked via individual keywords. This enables specific evaluations and allows our algorithm to better understand which content is didactically relevant for users.
While manual tagging is useful, it can also be time-consuming. That’s why we developed taggingatthe push of a button: Our authors can automatically generate suitable keywords after entering the task texts, remove them again if necessary and continue to add manual keywords. For this function, we use Natural Language Processing techniques. But what does that mean exactly?
How does auto-tagging through Natural Language Processing work?
The field of Natural Language Processing deals with the analysis of our language. Depending on the requirement area, sometimes simple statistics are enough for this. However, to produce intelligent results as needed in our case, more complicated methods must be used.
Word embeddings through high dimensional vectors
At the heart of our auto-tagging are so-called “word embeddings”. These translate words into high-dimensional vectors so that texts can also be understood by computers. Such vectors then allow us to make calculations and determine the proximity of words and texts to each other. For example, one can imagine that the terms “tax advisor” and “tax law” are relatively close. Exactly this proximity can be described by vectors. Of course, not all comparisons are so clear-cut. For example, which word should be closer to “tax advisor”: “lawyer” or “finance”? Both words have a different reference to “tax consultant”, which is why a clear, unambiguous answer is difficult.
Therefore, to capture all possible properties of a word, our word vectors consist of several hundred dimensions. In order for these dimensions to be meaningful, the model that translates the words into vectors must be trained beforehand – in our case with several hundred million words.
From vectors to tags
For generating the tags in chunkx, we first combine all the explanatory fields of a channel (i.e. title, description, questions, the correct answer, feedback) as a single vector. For thematically meaningful tags and lower computation time, all unnecessary filler words are filtered out of the texts. Now, to generate tags for a single task, the words are compared to each other as well as to the associated channel. The different sections are weighted differently and continuously readjusted.
The words whose distance from the channel vector is the lowest and which do not exceed a certain threshold are ultimately proposed to the author as tags .
Why are tags so important now?
The tag generation technology is not only a time saver for our authors, but also enables intelligent linking of content. For example, consider our learning content on the topic of tax law: A learner has knowledge gaps on the topic of sales tax. We can now repeat this selected content accordingly. However, we can also have our algorithm capture what learning content from other channels available to the learner has content proximity to the topic of sales tax. We can then suggest and prioritize these to him as he learns about one of these channels. The selection of content thus adapts to the learner and his learning time is used as efficiently as possible: Namely, with the content for which there is a need to learn.
While classic web-based training or learning videos offer the same content in the same order for all learners, with chunkx the most appropriate content can be selected – and not just within one channel, but across an infinite number of channels.
The more channels and topics are made available to employees of a company in chunkx, the more content overlaps arise and the more continuous micro-learning with chunkx shows its full strength.
Contact us
Have we aroused your curiosity or do you feel bored by our example around tax law? Well, let’s also rather talk about your topics and how we can best support learning about them with chunkx. Write to us and we’ll get back to you shortly.