Limitations of LMS and LXP
Traditional learning management systems (LMS) or learning experience platforms (LXP) do not directly access the content that learners are working on. Courses are linked via SCORM or other standards and may also be opened directly by the system, but exactly what content is in them is not known to the system. It usually only knows the metadata, such as the title and a short description. In some, and by no means all, cases, the system also knows what the learner’s progress is, such as being on page 5 of 20. However, the system does not know what was explained in terms of content on these first 5 pages and whether any gaps in the person’s knowledge were identified.
Learning content analysis in chunkx
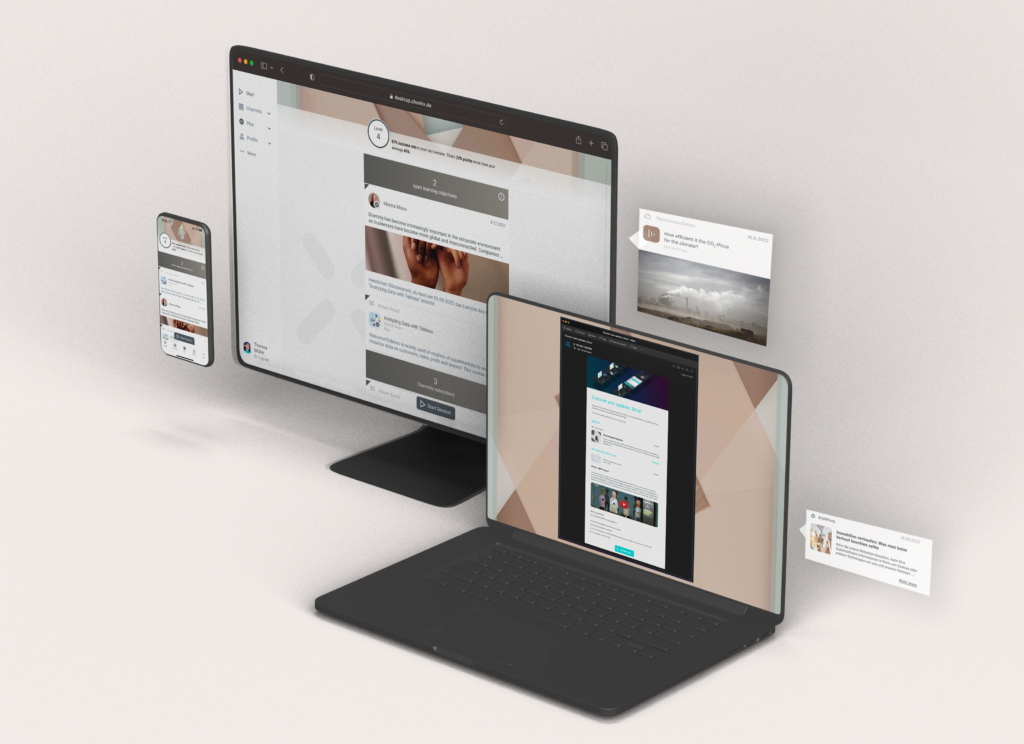
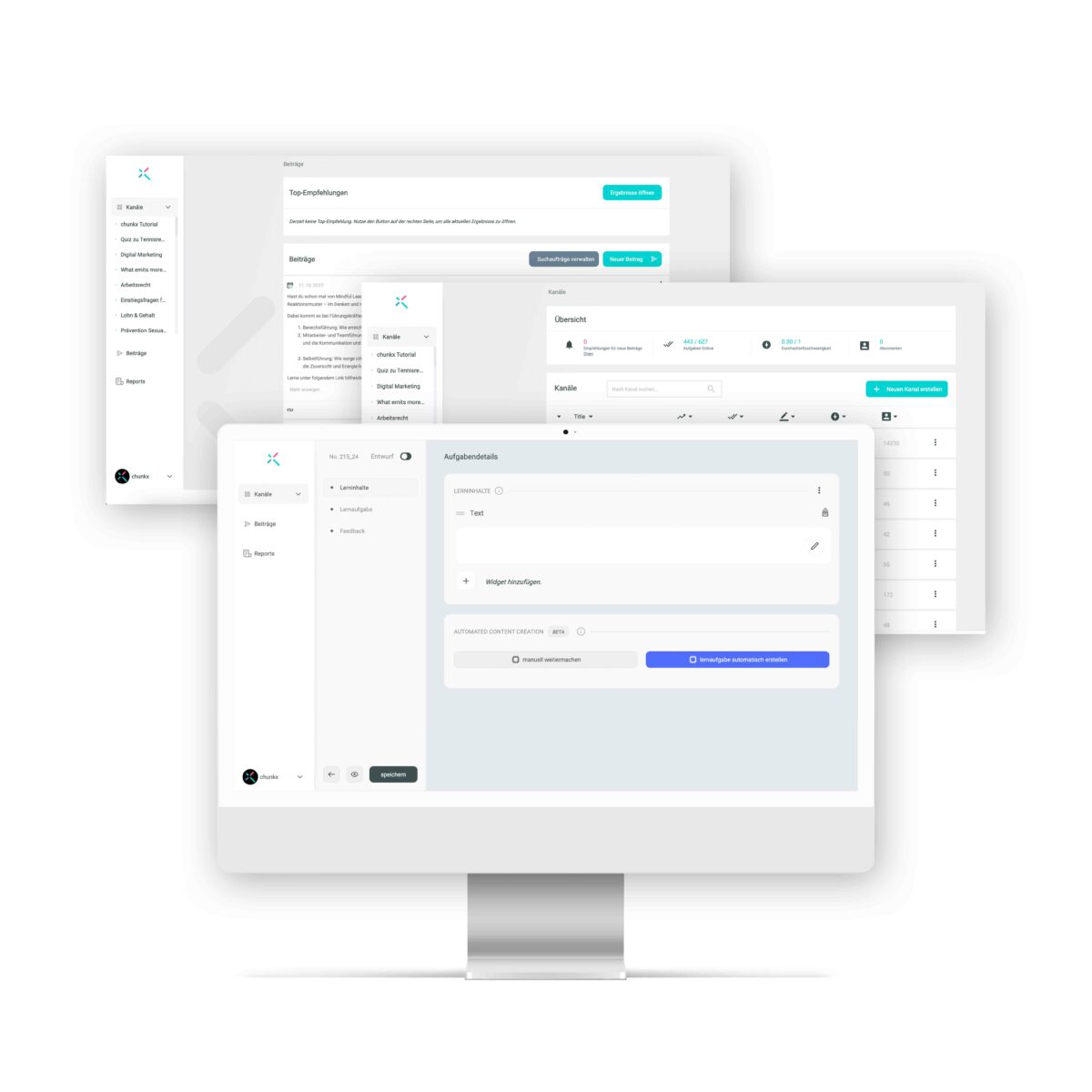
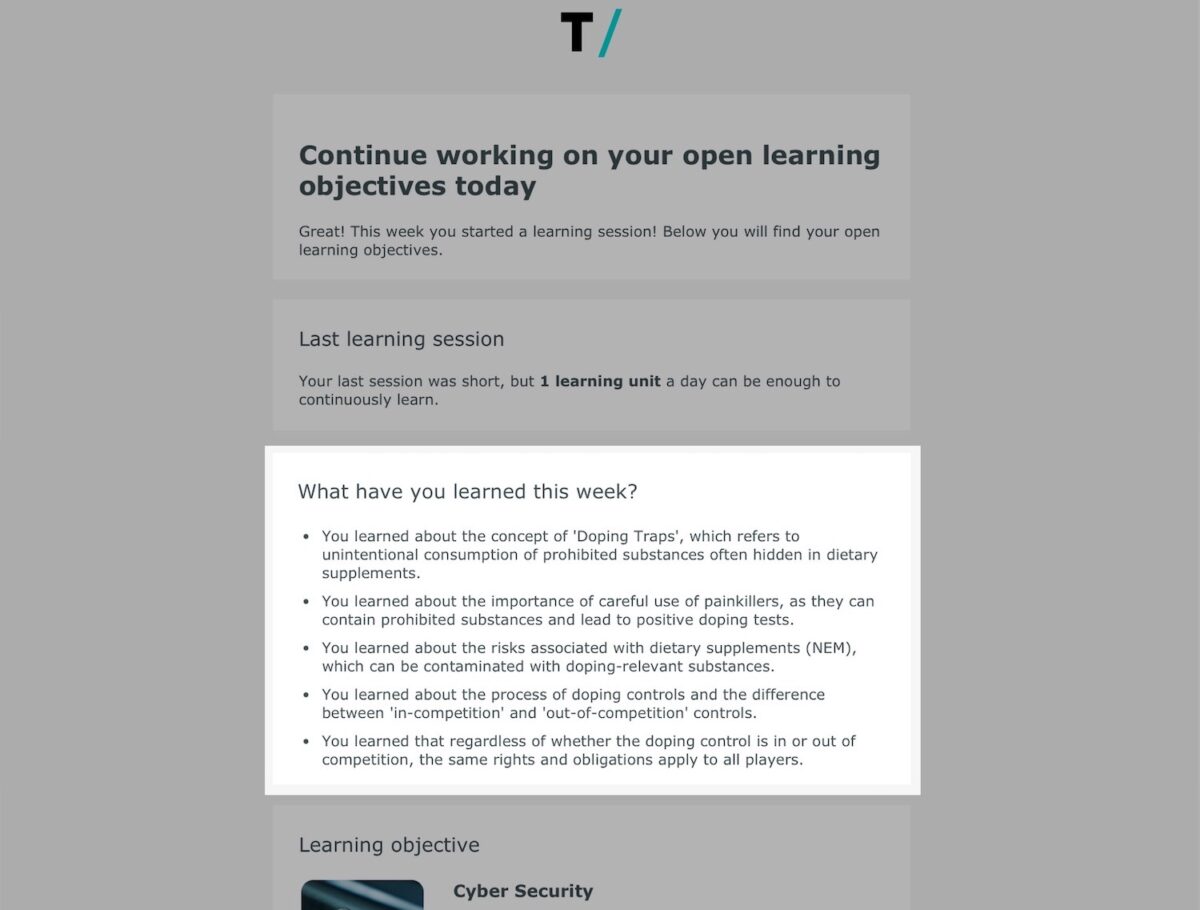
With chunkx, things are different: In chunkx, microlearning units can be created, managed and played out directly. Innovative AI functions also make it possible to transform the learning content of existing trainings and courses into microlearning units and continuously play them out to learners. In other words: Subscribe to the learning content. chunkx thus has direct access to the content and can evaluate which content has been worked on by a learner in a week. For each learning unit, the key message is identified and presented in the user’s language. If more than five core messages are generated in a week, data on the current state of knowledge in chunkx can be used to make the selection even more appropriate and, if possible, support where the most learning is needed.
Seamless learning
Reflecting on what you have already learned is one thing, learning something new is another. Each communication event in chunkx, such as the weekly learning review or new recommendations, is also used to calculate which microlearning unit should be selected next for the user. In this way, communication and information occasions are optimally used to provide a low-threshold opportunity for seamless further learning. The microlearning units themselves are presented as completely as possible in terms of content. So users are not only made aware, but learning can happen immediately. The channels used are email or MS Teams, also for the personalized summaries.

More AI features in chunkx
In chunkx, artificial intelligence and smart algorithms are used in a variety of ways:
- In content creation, to relieve authors and to efficiently transform existing learning content into microlearning units including learning tasks.
- In keywording, to be able to efficiently analyze and relate content.
- This is especially important for our adaptive learning algorithms. Here, we keep on using rule-based calculations, but we also experiment a lot in the areas of machine learning and AI.
- In skill analysis and referencing skill ontologies such as ESCO to relate content to standardized or company-defined skills.
- For recommendations for further learning. Again, the content is analyzed mathematically and related to other content, such as exciting articles, courses, or other learning units. Particularly exciting for companies and organizations with large product databases and knowledge bases: These can also potentially be used by us to provide learners with optimal recommendations.
- In personalizing learning content, such as the custom-created summaries shown here, which we will gradually incorporate at other places in our Learning Experience.
With chunkx, we’ve created the solution to turn your one-off learning activities into continuous learning experiences, such as personalized summaries. Talk to us about your learning culture and the changes in your organization and how chunkx can best support you.